Table of Contents
- Importing a Safetensors adapter
- Importing a Safetensors model
- Importing a GGUF file
- Sharing models on ollama.com
Importing a fine tuned adapter from Safetensors weights
First, create aModelfile with a FROM command pointing at the base model you used for fine tuning, and an ADAPTER command which points to the directory with your Safetensors adapter:
FROM command as you used to create the adapter otherwise you will get erratic results. Most frameworks use different quantization methods, so it’s best to use non-quantized (i.e. non-QLoRA) adapters. If your adapter is in the same directory as your Modelfile, use ADAPTER . to specify the adapter path.
Now run ollama create from the directory where the Modelfile was created:
- Llama (including Llama 2, Llama 3, Llama 3.1, and Llama 3.2);
- Mistral (including Mistral 1, Mistral 2, and Mixtral); and
- Gemma (including Gemma 1 and Gemma 2)
- Hugging Face fine tuning framework
- Unsloth
- MLX
Importing a model from Safetensors weights
First, create aModelfile with a FROM command which points to the directory containing your Safetensors weights:
FROM ..
Now run the ollama create command from the directory where you created the Modelfile:
- Llama (including Llama 2, Llama 3, Llama 3.1, and Llama 3.2);
- Mistral (including Mistral 1, Mistral 2, and Mixtral);
- Gemma (including Gemma 1 and Gemma 2); and
- Phi3
Importing a GGUF based model or adapter
If you have a GGUF based model or adapter it is possible to import it into Ollama. You can obtain a GGUF model or adapter by:- converting a Safetensors model with the
convert_hf_to_gguf.pyfrom Llama.cpp; - converting a Safetensors adapter with the
convert_lora_to_gguf.pyfrom Llama.cpp; or - downloading a model or adapter from a place such as HuggingFace
Modelfile containing:
Modelfile with:
- a model from Ollama
- a GGUF file
- a Safetensors based model
Modelfile, use the ollama create command to build the model.
Quantizing a Model
Quantizing a model allows you to run models faster and with less memory consumption but at reduced accuracy. This allows you to run a model on more modest hardware. Ollama can quantize FP16 and FP32 based models into different quantization levels using the-q/--quantize flag with the ollama create command.
First, create a Modelfile with the FP16 or FP32 based model you wish to quantize.
ollama create to then create the quantized model.
Supported Quantizations
q8_0
K-means Quantizations
q4_K_Sq4_K_M
Sharing your model on ollama.com
You can share any model you have created by pushing it to ollama.com so that other users can try it out. First, use your browser to go to the Ollama Sign-Up page. If you already have an account, you can skip this step.
Username field will be used as part of your model’s name (e.g. jmorganca/mymodel), so make sure you are comfortable with the username that you have selected.
Now that you have created an account and are signed-in, go to the Ollama Keys Settings page.
Follow the directions on the page to determine where your Ollama Public Key is located.
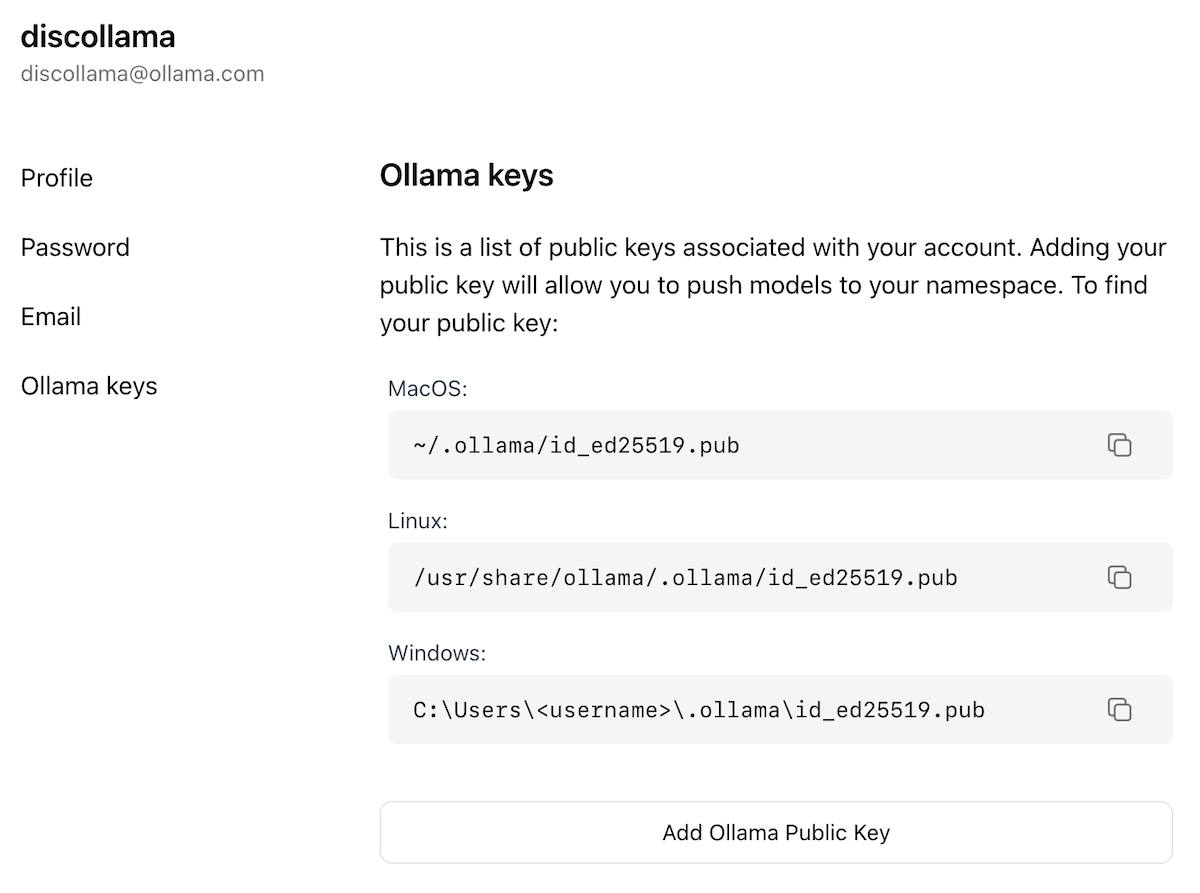
Add Ollama Public Key button, and copy and paste the contents of your Ollama Public Key into the text field.
To push a model to ollama.com, first make sure that it is named correctly with your username. You may have to use the ollama cp command to copy
your model to give it the correct name. Once you’re happy with your model’s name, use the ollama push command to push it to ollama.com.